
신문, 버스 지면 광고, 티비 방송을 통한 광고를 집행하던 시대는 지났죠. 소비자의 눈이 오프라인에서 온라인으로, 온라인 중에서도 웹에서 앱으로 넘어가며, attention span이 짧아짐에 따라 필요한 광고의 종류, 소재, 소요 시간 등이 많이 변화했는데요, 이를 통틀어 디지털 마케팅 시장으로 정의합니다.
이런 효율적인 광고를 집행하도록 돕는 솔루션들을 AdTech으로 정의하고 발달해왔으나, 최근 5년간은 광고의 집행 뿐만 아니라 데이터와 기술을 더 활용하여 매체 및 소재 설정부터 광고 효율 측정까지 대시보드 형식의 인사이트를 도출해주는 MarTech이 발달했습니다.
MarTech에 관심과 연구개발이 커가짐에 따라 이제는 실시간으로, 혹은 유저가 원한다면 자동으로 광고의 매체, 소재 설정 및 집행까지 자동화하여 효율을 최적화 해주는 솔루션으로 MarTech 시장이 2.0으로 발전하고 있습니다.
조금더 자세한 설명들은 아래를 참고 해 주세요.
0. 디지털 마케팅
•
인터넷, 모바일 사용의 꾸준한 증가로 인해 디지털 마케팅 시장의 성장은 자연스러움
◦
국내시장 case
▪
2020년 코로나 19 영향과 경기 둔화로 인해, 국내 전체 광고 시장 규모는 -5.3% 예정
▪
이러한 역성장에도 불구하고 ‘디지털 광고’ 시장 규모는 6% 성장
•
디지털 광고 시장의 확대 속에서, 해당 시장을 이끄는 광고주와 매체는 명확한 각자의 니즈를 가짐
◦
광고주들은 효율적인 광고 집행을 원함
▪
최소한의 비용으로 최대한의 목적(설치, 구매 등)을 달성하고자 함
◦
매체는 높은 광고 수익을 원함.
▪
높은 단가를 제시하는 광고주를 확보
▪
활용 가능한 inventory를 모두 판매 (=비어있는 inventory 최소화)
◦
이러한 양 side 사이에서 최적화된 지점을 찾기 위한 기술이 필요해짐
1. Martech 1.0
•
Adtech 이후 Martech 1.0이 등장한 이유 : Adtech가 커버하지 못하는 마케팅 개선의 영역 존재
◦
마케팅의 경우, ‘광고 setting → 집행 → 트래킹 → 결과 분석’의 사이클로 진행됨
◦
이 때 결과에서 도출해내는 insight를 다시 setting에 반영하는 것이 중요함
◦
하지만 Adtech는 ‘집행’의 효율에만 집중
◦
마케팅의 사이클을 지속적으로 성장, 개선시키기 위해서는 Martech가 필요
•
Martech : 데이터와 기술을 활용하여 최적의 마케팅 시도하는 것
◦
그로스해킹, 퍼포먼스 마케팅, 데이터드리븐 마케팅 등
2. Martech 2.0
•
Martech 1.0에서 Real time으로 데이터 트래킹 및 수정 가능하게 만든 기술 혁신
◦
1.0의 경우 데이터를 가져오는데에 일반적으로 1시간~1일 소요 (예약된 배치 데이터를 가져오는 형식)
◦
But 2.0의 경우 10초 이내에 데이터를 가져옴
▪
주문형으로 데이터 가져오는 형식 (사용자가 액션을 할 대 해당 채널에서 데이터를 바로 가져옴)
▪
기술적으로 구현하기 매우 어려우며 해당 아키텍처를 구축하기 위해서는 1.0 솔루션에서 수정하는 것이 아니라, 처음부터 구축해야 함 → = 기술혁신
•
Why real time?
◦
최신 데이터를 실시간으로 확인하며 문제를 파악
◦
데이터를 수정하고 직전에 수정된 데이터 확인이 가능함
▪
2.0이 아니라면 사용자는 데이터를 보는 것만 가능
◦
광고주의 가장 명확한 니즈이자 Adtech와 Martech이 등장하게 된 이유였던 광고 효율화를 혁신적으로 실현
▪
특정 ‘시점’의 데이터가 아닌, 실시간으로 변화하는 데이터를 보며 최대한 효율적으로 대응
◦
COVID-19 영향으로 격변하는 시장 상황 속에서, 마케터는 인사이트에 기반하여 최대한 빠르게 광고를 집행해 한다는 사실은 더욱 자명해짐
•
Martech 2.0의 성장세
◦
Adverity는 Softbank Vistioin Fund로부터 1억 2천만 달러 조달
3. Martech 3.0
•
CPI/CPA/CPS 기준의 마케팅 방식에서 브랜드 마케팅으로
•
퍼포먼스 마케팅은 타게팅 대상자 모수 증대 보다 컨텐츠 차별화 집중
•
First Party 쿠키 수집을 통한 CRM 캠페인 강화
•
Zero Party 데이터 수집으로 유저 관심 세분
•
제로 파티 데이터는 고객이 직접 자신의 언어로 데이터를 전달하는 것이고, 퍼스트 파티 데이터는 고객의 행동으로 데이터 를 제공하는 것이라는 데서 차이점이 있음
•
하지만 커머스의 관점에서는 본질적으로 두 데이터가 모두 고객으로부터 동의를 받아 직접 제공받았다는 공통점이 있
해외 선두기업
•
Klaviyo : 데이터 기반 마케팅 자동화 솔루션
◦
Series D, $320M, 2021년 5월, Sands Capital
◦
누적 투자금액 $675M
◦
기업가치 $9.15B
◦
유사점: Customer profiles, transactions, browsing history, support tickets, website events, text messages—all updated in real time for lightning-fast segmenting.
•
Adverity : 지능형 데이터 통합 및 분석 플랫폼 제공사, 아드리엘과 매우 유사
◦
2015년 설립, 오스트리아 비엔나, 런던, 뉴욕
◦
2020 revenue $15.7M
◦
투자정보
▪
Series D, $120.0M, 2021년 8월
▪
Sapphire Ventures, Softbank Vision Fund
Market Sizing
15B
•

Reference
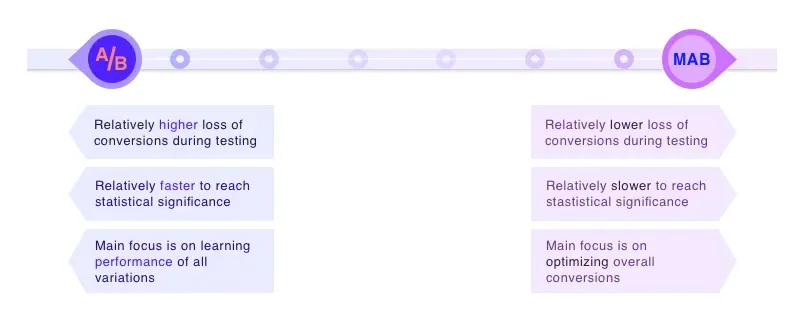
MAB in A/B Testing
•
Multi-Armed Bandits is a type of A/B testing that uses ML to learn from data gathered during the test to dynamically increase visitor allocation in favor of better-performing variations
•
Variations that aren’t good get less and less traffic allocation over time
•
Core concept of MAB is ‘dynamic traffic allocation’ – it’s a statistically robust method to continuously identify the degree to which a version is outperforming others and to route the majority of the traffic dynamically and in real-time to the winning variant
•
It’s a exploration vs. exploitation optimization
◦
most classic A/B tests are by design in exploration mode, after all determining statistically significant results
◦
MAB leans towards exploitation
•
Thompson Sampling is the mathematical concept to direct a higher percentage of traffic to best-performing variation
•

•
CRM Marketing
•
세그먼트 기반 추천 : 소비자의 기호가 성별, 나이 등의 정보에 의해 확실히 구분 되고 상품의 양이 많지 않은 경우 효과적 e.g., ‘인기순,’ ‘신상품순’; 상품 종류 다양화에 따라 장기적 효과 감소
•
개인화 추천 : 고객이 플랫폼에 들어와 클릭한 것들, 찜한 것들, 구매한 것들 바탕으로 실시간으로 소비자가 가장 좋아할 만한 것 맞춤형으로 추천
•
개인화 추천은 소비자 데이터 및 KPI에 따라 모델 설계 방식이 달라지고, 내재화 하기에는 MLOps + 모델 R&D + 데이터 파이프라인 + KPI 설정을 할 수 있는 팀 구성이 필요하기에 내부적으로 자체 구현하기 어려움
•
CRM 마케팅의 세 축
◦
방문 패턴 : 언제 어느 채널 통해 방문했는지
◦
구매 패턴 : 언제 얼마나 자주 구매 하는지
◦
관심 : 어떤 상품에 관심을 갖고 있는지
◦
퍼널 차트 회원방문 / 구매 세그먼트 차트에 우선적으로 집
•
SDK 위치
◦
홈 화면
◦
장바구니
◦
상세 페이지
◦
검색 결과 페이지
•
성장시킬 수 있는 주요 KPI
◦
월 거래액, 클릭
•
개인화란 ?
◦
무엇을 - 상품/프로모션
◦
누구에게 - 발송 타겟
◦
언제 - 발송 타이밍
◦
어떻게 - 문구/이미지
•
개인화 Productized
◦
최적의 세그먼트 추출 : 특정 상품에 대한 기획전을 진행하고 싶은 경우, 해당 기획전에 가장 반응할 만한 유저들을 자동으로 추출
◦
개인화 랜딩페이지 : 캠페인 클릭 시, 유저별로 가장 클릭/구매할 확률이 높은 상품이 진열된 페이지가 노출
•
Braze의 한계점
◦
다양한 필터 (Rule)을 걸어서 발송 타겟을 추출 할 수 있게 도와주지만, 최고의 효율을 내는 세그먼트를 찾기 위해서는 수없이 많은 실험을 반복해야 함
◦
복잡한 기능들을 활용하려면 learning curve 가 필요
▪
Add-on 계약을 해야 함
▪
API 연동 프로세스
▪
AI 기술에 대한 이해도
CDP (Customer Data Platform) vs. DMP (Data Management Platform)
•

•
종종 세컨드파티 데이터, 서드파티 데이터로 보강될 때도 있으나 통상 퍼스트파티 데이터(자사 데이터)가 사용되는데요. 그러기에 CDP는 이미 내 사이트에 방문한 경험이 있는 고객을 대상으로 하는 마케팅, 기존 고객의 이탈 방지나 참여 및 구매 유도 마케팅에 주로 사용되죠.
•
DMP는 개인 식별이 되지 않는 정보(서드파티 데이터)를 주로 활용한다는 점에서 CDP와 차이가 있습니다. 즉, DMP도 고객데이터를 수집하지만 개인화 마케팅을 위해 활용되지는 않고 있는 것이죠. DMP는 웹 및 앱 데이터, 마케팅 및 광고 캠페인 데이터 등을 주로 활용하는데요.
•
DMP는 특정 회사에서 사용하는 것이 아닌 광고주와 매체사에게 서로 다른 소프트웨어를 제공하여 서로 광고 서비스를 판매/구매할 수 있게끔 하는데요. 마케터는 DSP(Demand Side Platfom, 공급중심 플랫폼)를 통해 광고 영역을 구매하고, 매체사는 SSP(Supply Side Platform, 수요중심 플랫폼)을 통해 광고 영역을 판매하는 것입니다.
•
CDP와 DMP 내에서도 솔루션별로 약간의 차이가 있으나, 크게 봤을 때 CDP와 DMP가 서로 보완할 수 있는 영역이 있는 것도 자명합니다. 예를 들어, CDP는 기본적으로 로그인 고객의 데이터 수집에서 크게 강점을 보입니다. 하지만, 평균적으로 개방형 웹의 경우 20%가량의 방문자만이 로그인을 진행한 상태이죠.(Democratizing AI: Changing the game for broader AI adoption, 2022) 즉, 방문자의 80%에게 아웃바운드 마케팅을 진행하기는 어렵습니다. 이런 상황에서 DMP는 중요한 보완책이 될 수 있죠.
•
CDP는 공개된 개인 정보를 활용하는 것이고, DMP는 공개되지 않은 익명 정보를 활용하는 것이죠. 결국, 데이터를 잘 다룬다는 것은 이러한 다양한 데이터를 적재적소에서 잘 통합하고 결합하는 데 능숙한 사람이라고 볼 수 있죠.
•
◦
Data CDPs : 데이터 수집 및 저장 focused
▪
다양한 소스 고객 데이터 수집, 해당 데이터를 하나의 고객 ID에 연결
▪
이 결과를 외부 시스템에서 활용할 수 있는 데이터베이스에 저장
▪
e.g., Google Analytics, Adobe Analytics, Ace Counter
◦
Analytics CDPs : 데이터 분류 및 분석
▪
데이터 조립과 분석 응용 프로그램을 통상적으로 의미
▪
고객 세분화 기능 제공, ML, 예측 모델링, Attribution modelling, Customer Journey
▪
e.g., Dighty
◦
Campaign CDPs : 내부 페이지 메시지 전달
▪
데이터 조립, 분석과 더불어 내부에서 마케팅 액션 제공
▪
인하우스 내 개인화 메시지 노출, 고객과의 실시간 상호 작용 또는 제품, 콘텐츠 추천
◦
Delivery CDPs : 외부 페이지 활용 메시지 전달
▪
e-mail, mobile push, SNS 광고등을 통해 외부로 메시지 전달
▪
딜리버리 플랫폼은 외부 메시지 전달은 진행할 수 있지만, 전체 고객데이터가 저장된 시스템이 아니기에 타겟 고객 데이터를 불러올수 있는 시스템 필
•
유저의 행동을 이해하고 성향을 파악하여 유저에게 유익한 정보를 제공하는 것
•
Intention : for 전체유저 // 새로운 유저 유입
◦
인텐션 학습의 재료는 키워드 : 특정 기간 내 출현하는 횟수가 많은 검색어일수록 키워드 성향이 강한 것으로 판단
◦
인텐션을 최적으로 학습하기 위한 정답셋이 필요함 : 매일 쌓이는 수많은 로그 중에서 정답셋이 자동으로 추출되도록 구현; 각종 카테고리, 외부사이트, 카페/블로그, 커머스 상품 등의 메타 정보 활용
◦
1/ 유저로그 + 메타 정보 키워드화 : 유저-키워드 Map
◦
2/ 인텐션 별 정답셋 Supervised Learning : 인텐션별 프로파일
◦
3/ Probability Estimation : 유저별 인텐션 스코어
◦
유저 1명당 400+개의 인텐션 스코어가 존재
◦
유저별 인텐션 스코어를 이용한 다각적인 분석
◦
인텐션간 조합을 이용한 새로운 정답셋 정의
•
Attention : for 활성유저 // 유입된 유저를 구매에 도달하게 하기
◦
어텐션 학습의 재료는 정규식 e.g., /like, /menubar, /popup
◦
1/ 서비스별 유저로그 정규화 : 유저-액션 Map
◦
2/ 어텐션 별 정답셋 Supervised Learning : 어텐션 별 프로파일
◦
3/ Probability Estimation : 유저별 어텐션 스코
•
Retention : for 구매유저 // 구매경험 있는 유저가 이탈하지 않게 유지
Market & Regulations
•
First Party Cookie : 고객이 내 사이트에 방문했을 때 내 사이트에서 직접 그 고객에 대해서 쿠키를 발급하는 쿠키
•
Third Party Cookie : 페이스북 픽셀, GDN, 모비온, 크리테오 같이 리타게팅 플랫폼에서 발급한 쿠키
•
2017 : 애플 사파리 Third Party 쿠키 수집 제한
◦
사파리 브라우저용으로 지능형 추적 방지(Intelligent Tracking Prevention)라는 기능을 출시했습니다
◦
사파리가 쿠키를 관리하는 방법, 특히 타사 컨텍스트에서 쿠키에 액세스하는 기능을 변경합니다
•
2018 : EU 27 개국 GDPR 적용
◦
General Data Protection Regulation
•
2019 : Google Chrome Privacy Sandbox
◦
Initiative led by Google to create web standards for websites to access user information without compromising privacy.
◦
Core purpose is to facilitate online advertising by sharing a subset of user private information without the use of third-party cookies.
◦
e.g., Topics API (formerly Federated Learning of Cohorts or FLoC), Protected Audience, Attribution Reporting, Private Aggregation, Shared Storage and Fenced Frames
◦
On September 7, 2023, Google announced general availability of Privacy Sandbox APIs, naming explicitly Topics, Protected Audience, Attribution Reporting, Private Aggregation, Shared Storage and Fenced Frames, meaning these features were enabled for more than half of Google Chrome users.
◦
follow the idea of k-anonymity and are based on advertising to groups of people called cohorts instead of tracking individuals. They generally place the web browser in control of the user's privacy, moving some of the data collection and processing that facilitates advertising onto the user's device itself
◦
three focuses within the Privacy Sandbox initiative: replacing the functionality of cross-site tracking, removing third-party cookies, and mitigating the risk of device fingerprinting
◦
Delivered Tech
▪
Topics API : aims to provide the means for advertisers to show relevant content and ads by sharing interest-based categories, or ‘topics’, based on recent browsing history processed on the user device. Google Chrome, the only mainstream browser supporting Topics API. As of December 2023, Google Chrome allows users to disable sharing of the interests via Topics API in browser's Settings.
▪
Fenced Frames API : an embedded frame type that is not permitted to communicate with a given host page, making it safe to access its unpartitioned storage as joining its identifier with the top site is impossible. FLEDGE-based will only be allowed to be displayed within Fenced Frames, although for the purpose of current testing it is still permissible.
▪
Attribution Reporting API : facilitates conversion tracking, for example recording whenever a click on an ad or a view results in a purchase, while suppressing the ability to track users across multiple websites.
▪
Protected Audience API : designed for targeting of interested audiences, including through retargeting. It allows vendors selected for advertising to take an advertiser’s website data and to place users in interest groups specifically defined for a given advertiser, meaning that users can see tailored ads, with no infringement on their privacy. Prior to reaching global availability on August 17, 2023, the technology was known as "First Locally-Executed Decision over Groups Experiment", (FLEDGE).
▪
Shared Storage API : addresses a need for browsers, for legitimate cases, to store information in different, multiple, unpartitioned forms, rather than separately as the prevention of cross-site tracking generally dictates. Despite being unpartitioned, Shared Storage API ensures data can only be read in a secure environment.
▪
Private Aggregation : tracks some aggregated statistics across ad campaigns.
•
2021 : 애플 ATT 정책 IDFA 수집 방식 변경
◦
App Tracking Transparency : 광고 추적을 위한 동의 팝업을 의무적으로 거치도록 변경
◦
IDFV : IDentifier For Vendor ; IDFA 를 못받아 내는 경우 대신 사용. 확정적 어트리뷰션 모델 적용 안되고, 확률적 모델만 작동
◦
IDentifier For Advertisers : 광고식별자
▪
IDFA 전에는 UDID 라는 변경 불가 고유 식별자 값을 사용하였으나, UDID 가 유출되면서 이슈들 발생, 이로 인해 2013년에 UDID는 변경이 가능한 IDFA로 대체
▪
기존의 광고주는 IDFA를 통하여 디바이스를 식별, 이를 통해 리타겟팅과 같은 맞춤형 광고제공 가능
▪
Default로 설정되어 사용되고 있고, 광고 추적 제한을 걸 경우에만 차단
▪
Device-level insight 제공 불가, 실적 공유 가능
◦
SKAd Network (SKAN): 애플이 추천하는 자사서비스로써 IDFA 나 다른 광고 ID 없이 사용 할 수 있는 새로운 대안
▪
사용자의 동의를 받을 필요가 없기 때문에 애플의 개인정보보호 기준을 준수하면서 iOS14 이슈에서 리스크 줄일 수 있음
◦
Third party 기반 타겟팅 광고 시장이 키워드 광고 시장으로 옮겨감
•
2024 : 구글 크롬 Third Party 쿠키 수집 제한
•
We don’t have deterministic models anymore due to third party cookie ban
•
We need to use probabilistic models for x% of the entire sample size and exprapolate from that
•
MarTech sits at the intersection of Product, Growth, Engineering and Marketing
◦
One piece is people and process
◦
The other piece is system and the platform
•
Growth acquisition person is using a CDP to send data to ad network to run ads
•
30-40 people start-up may use third party solutions like Amplitude along with maybe built-in first party solution on top of it
•
B2B is a bit more complicated, B2C is simpler in that you acquire customers, get them to product, so CDP is the source of truth a lot of the times
Marketing Stack
•
SMS : Postscript, Attentive
◦
Attentive and Postscript both provide merchants with the ability to easily design and deploy popups on their Shopify sites via their opt-in unit builders. Merchants can customize the design, copy, and display behavior, as well as configure different units for mobile and desktop.
•
e-mail : Klayvio
•
CS : Gorgias, Zendesk
•
Reviews : Okendo
•
Retention : Yotpo
Global Landscape
•
Snowplow : [CDP] Behavioral Data Platform. Can design Product schema, User schema, Event schema. Unlike other CDPs that can only do User object or Event object. So you can either stuff as a user property on a User object, or you can stuff the data on an Event and fire it off as an event
•
Birdseye : 500K in seed funding
◦
Market Recommendation :
◦
Customer Insights :
◦
Campaign Management :
◦
Team Assignment :
•
Sendlane : TechCrunch article
◦
Founded in 2018; vision is to create meaningful interactions between customers and retailers
•
Sendinblue : TechCrunch article
◦
Raised >$160M; positioning itself as a consolidator, acquiring smaller martech start-ups, also building CRM tools
•
Sarbacane : TechCrunch article
◦
Another French start-up, >$30M funding
◦
SaaS-based tool that lets businesses craft, send out, measure and respond to marketing campaigns over email and text messaging, which is sold as Sarbacane in France and Mailify outside of Francophonic countries
◦
Layout for email design, Sarbacane Chat (for running chatbots) and Touchdown (a kind of all-in-one, multichannel marketing platform akin to Salesforce’s or Adobe’s marketing clouds but just for Microsoft Dynamics users), and it has more recently started to also grow by way of acquisition, acquiring the Datananas B2B prospecting platform to get deeper into CRM.
•
Cordial : TechCrunch article
◦
personalizes and automates cross-channel messaging campaigns
◦
$50M Series C
•
Iterable : TechCrunch article
◦
$60M Series D
•
Segment :
•
Amplitude :
•
Mixpanel
•
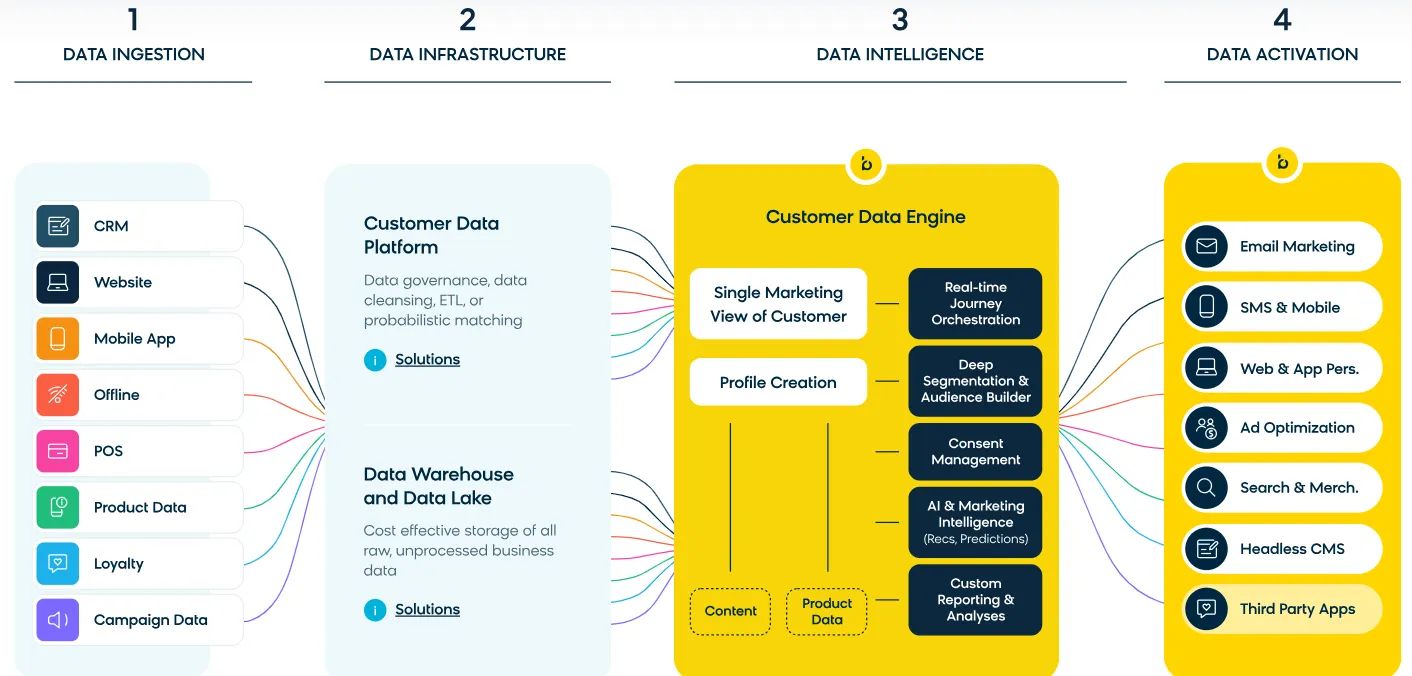
Bloomreach : Plug Bloomreach into your existing, enterprise-wide data investments like a CDP, data lake, or data warehouse to visualize and activate that data for subsequent orchestration and personalization.
◦
Bloomreach’s customer data engine is the data & analytics core that drives our email marketing and all other products. It brings together customer data platform capabilities and advanced analytics, and it’s this combination that enables marketers to understand their users’ journeys in real time and create personalized marketing campaigns that drive results. Learn more about how it works here.
◦
With Bloomreach Engagement, retargeting with the most relevant channel is no longer a guessing game. Using first-party data and AI predictions, you can segment your audience to reach customers in the places they are most active and streamline their path to purchase.
◦
Contextual Personalization : Similar to MAB, feels a bit too engineering heavy for non-techy marketers to use
•
◦
Marketing Automation :
▪
Loomi automatically determines the best email, SMS, or web content to show each individual customer (and when to send it) to maximize conversions.
▪
predicts the probability of purchase, churn, and order return to determine the right marketing cadence and content.
▪
Based on each customer’s purchase and browsing history, Loomi serves highly relevant and personalized product recommendations.
▪
monitors each customer’s average purchase frequency and automatically reminds them when they’re near the date of repurchase.
▪
LTV or purchase intent to generate lookalike customer segments on ad platforms, resulting in lower CAC.
◦
eCommerce Search and Merchandizing
▪
automatically finds similar products and product recommendations to avoid zero-result dead ends.
▪
automatically identifies the best opportunities to improve revenue and areas where your team should spend their time first.
◦
Content Management
▪
automatically creates and proofreads content — including product descriptions — for landing pages
▪
determines each visitor’s segment based on behavior and shows them personalized pages down to the component level.
▪
automatically generates tags and metadata from bodies of content.
◦
Conversational Shopping
•
Braze Interval
•
Salesforce Marketing Cloud
•
Adobe
◦
◦
▪
The combination of Marketo and Adobe’s Experience Cloud will form the definitive system of engagement for B2C and B2B enterprise marketers. Marketo’s exceptional lead management, account-level data, and multi-channel marketing capabilities will combine with Adobe’s rich behavioral dataset to create the most advanced, unified view of the customer at both an individual and account level. The result will be an unprecedented level of marketing engagement, automation, and attribution power, all with a goal of delivering end-to-end, exceptional experiences for our customers, where and when they want them.
▪
2018.08 : Adobe bought Marketo from Vista Equity Partners for $4.75 billion.
▪
Marketo Measure : Formerly Bizible, acquired by Adobe
•
Metaplane : End-to-end data observability platform
◦
Data from any channel — online and offline.
Collect data from across all your engagement channels. Then put that omnichannel data to work as it gets standardized and connected into a complete customer journey — all powered by Adobe Experience Platform.
Streaming data collection offers up-to-the-minute customer views and behaviors.
Data collected as customers move from online to in-store to call center and more.
Fully correlated data gives you unlimited breakdowns of any data element across any channel without writing SQL statements.
IDs from multiple channels and devices are connected into a single, unified customer profile.
•
B2C vs. B2B in terms of MarTech tools
B2C
•
2016 - 2017 : The rise of the CDP; collect a user, tie a bunch of data, track actions to performance ad networks, e-mail marketing tools, product analytics tools
◦
one centralized CDP; integrate one SDK, send all the data to all the other tools, create audiences
◦
Outreach, Salesloft, Salesforce, Pipedrive, Marketo, Pandadoc, Stripe, Yesware, Conga
◦
Segment :
◦
mParticle : has a ReverseETL functionality
◦
Rudderstack : RudderStack provides a customer data infrastructure solution for developers, data analysts, and product teams. Has ReverseETL functionality
◦
Census : lets you sync your customer data from a data warehouse to all your business tools. Designed for business ops teams that want to leverage data without relying on engineering.
▪
Census connects directly to your data warehouse and syncs data into apps like Salesforce, Marketo, and Google Sheets to help customer success, sales, and marketing be more effective.
▪
We provide a simple interface to control how data is mapped and how frequently it’s synced. Users can transform their data using SQL or tools like dbt. All of these pipelines are automatically monitored so users can uncover anomalies before the business is impacted.

▪
One-Click-Audience : Now, Census users can send their audiences to all major ads platforms (such as Facebook, Google, and LinkedIn) with a single click
•
Census auto-generates audience syncs that:
◦
Maximize match rates by sending as many customer identifiers as possible to each ads tool
◦
Ensure proper data format, hashing, and normalization
◦
Remove audience members in the destination, if they’re removed in the source
◦
Keep marketing audiences fresh with daily updates
•
Marketers can export their audiences directly to 200+ engagement channels without needing to import CSVs or write SQL
•
Advertising platforms take a “basket of identifiers” and try to match as many as possible to their user base. As a result, a data team can describe the datasets that are used in marketing audiences, then Census can automatically map that data to each individual ad platform. By sending as many identifiers as possible to each destination—and ensuring they’re properly hashed and normalized according to each platform’s specific rules—we maximize your advertising match rates. 이게 무슨 뜻인지?
•
2020 - 2021 : cost of ownership of warehousing became much cheaper; now starting to make sense to centralize all data warehousing in something like a Snowflake
◦

◦
How we move data around still a totally different animal; there is a way to get your data into the warehouse, and then how you activate it is completely independent from the CDP
▪
You could use Amplitude as your CDP, and then stream data into Snowflake
▪
And then use reverse ETL to pipe the data wherever you want e.g., Segment, mParticle, Rudder Stack has a reverse ETL function
◦
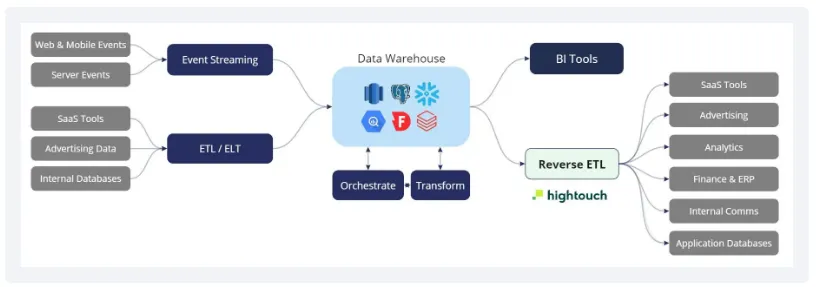
ETL (Extract, Transform, Load) : process of bringing data from disparate sources into the central data warehouse; more modern set-up is closer to ELT
▪
dbt (data build tool) is a data processing framework, based on Python, that allows to apply transformation on data inside a data warehouse like Snowflake, Redshift, BigQuery, PostgreSQL. dbt is the T in ELT
▪
It takes your code, compiles it to SQL, and then runs against your database
•
Models : where you write your SQL models
•
Tests : where you store your data
•
Macros : where you define macros to simplify your SQL code
•
Analysis : where you write SQL code to analyze data
•
Logs : generated when a ‘dbt run’ command is executed
•
Target Directories : created when compiling, running, or building documentation

◦
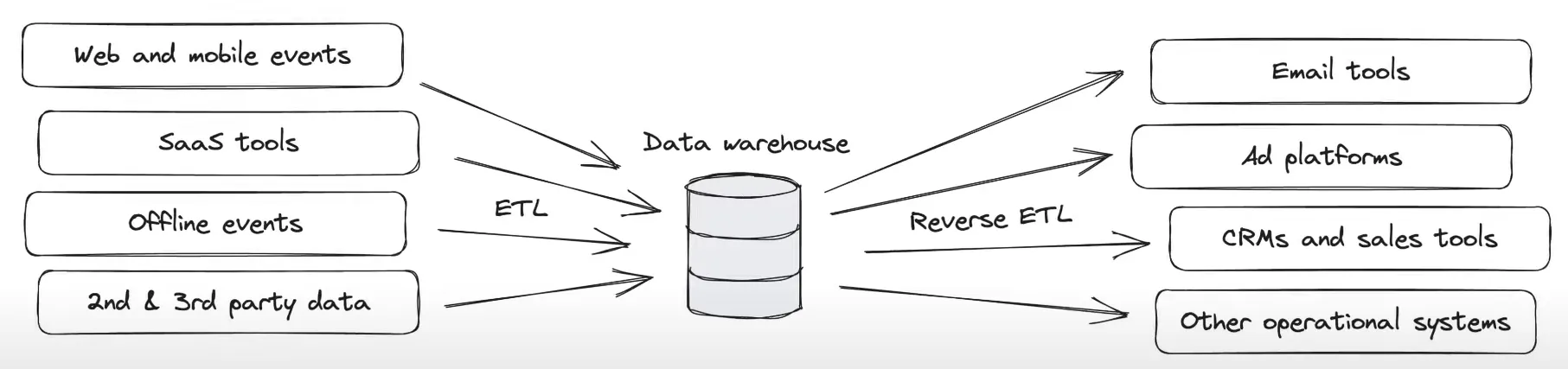
rise of reverse ETLs : taking data from the warehouse into operational systems like e-mail tools, ad platforms, CRMs and sales tools
◦
e.g., take Last Login from Snowflake and and stream it directly into Salesforce
◦
copying data from your central data warehouse to your operational systems and SaaS tools so your business teams can leverage that data to drive action and personalize customer experiences
◦
Both methods make use of batch processing.
◦
ETL is primarily used to power analytics use cases and consolidate disparate sources into a single unified view, while Reverse ETL is used to power Data Activation use cases
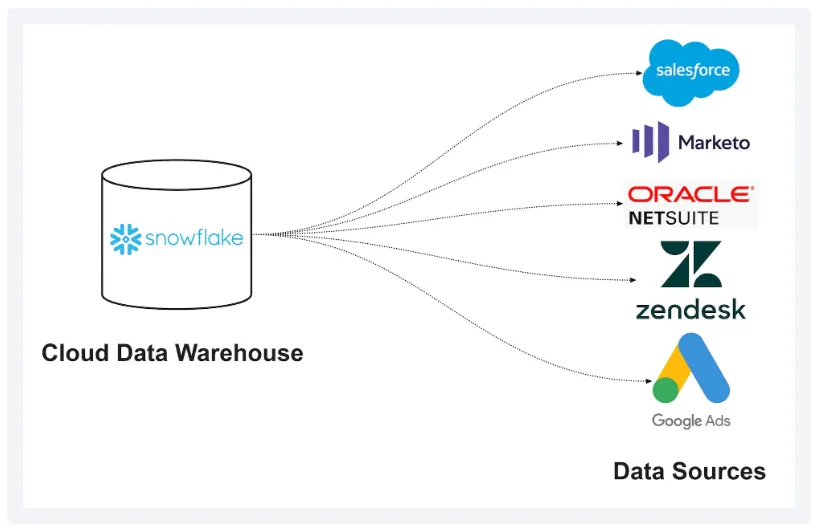
◦
Four Components of Reverse ETL
▪
Sources : represent the location where your business data is stored. Most of the time, this is a data warehouse like Snowflake or Google BigQuery.
▪
Models : consist of SQL statements that define how your data is represented and what data you want to pull from your source.
▪
Syncs : allow you to define the data from your model and declare how you want those records to be mapped to the appropriate fields in your end destination.
▪
Destinations : include any location that you want to send your source data to or where your business users consume this data (e.g., Salesforce, Google Ads, Iterable, Braze, etc.)
▪
◦
Instead of forcing your analytics team to train your sales reps to use BI reports, what if you could empower your analysts to feed lead scores from your data warehouse into a custom field in Salesforce? This is the exact type of use case where Reverse ETL excels.
Point to point solution vs. Hub & Spoke
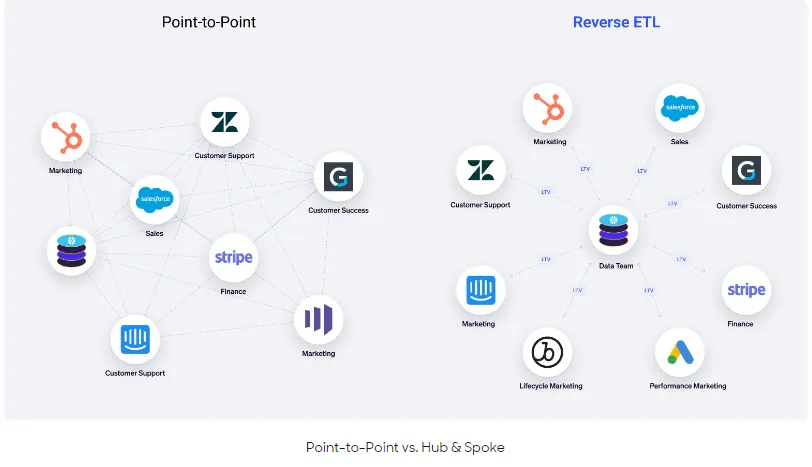
Limitations of CDP
•
CDPs operate as their own separate entity, which means they store data outside of your infrastructure, which can have significant implications around GDPR, CCPA, and HIPAA.
•
CDP implementations can take upwards of a year, and that’s not even accounting for the onboarding time it takes to train your teams on how the tool works. These platforms also impose instructions on how your data can be stored and modeled, usually requiring everything to fall within user and account objects.
•
place restrictions on how long you can access historical data, and you inevitably end up paying for an additional layer of storage even though all of the data you need to power your customer-facing use cases already lives in your data warehouse, to begin with.
•
Reverse ETL tools aren’t encumbered with these limitations because they operate and integrate with your existing tools and technologies. With Reverse ETL, you’re never storing data, you’re simply reading from your warehouse and writing the results of that query to your destination. This creates a Composable CDP architecture on top of your existing data warehouse, giving you increased flexibility to uniquely solve your use cases
Reverse-ETL Companies
•
Hightouch: Hightouch is a Reverse ETL platform that is designed for data teams and marketing teams. The platform supports 150+ destinations, and it integrates with a variety of data tools like dbt, Fivetran, Looker, etc. It offers version control, a live debugger, and support for alerting. For non-technical users, Customer Studio provides a no-code option so your business teams can self-serve and granularly build audiences using the parameters your data team has set in place
•
Census: Census is a Reverse ETL platform that offers a number of features for moving data from your warehouse to numerous destinations, but it’s not quite as flexible as Hightouch when it comes to developer-friendly and marketing-friendly features.
•
Segment: Segment is a traditional CDP. However, the company recently dipped its toes into Reverse ETL and is now offering warehouse-first capabilities. Many of the features end up being tightly coupled with the platform’s existing CDP offerings.
Build vs. Buy
•
Building custom Reverse ETL pipelines can become complicated very quickly
•
Every third-party API is constantly updating and changing, so you'll either have to download/upload manual CSV files or build a unique integration for every tool in your data stack.
•
You'll also have to monitor and manage each integration because a single API change can break your entire data flow, and this isn't even mentioning all of the other factors you have to consider: authentication, batching, rate limits, field mapping, parallelizing, error handling, monitoring, etc.
•
Reverse ETL platforms take on the cumbersome problem of managing API integrations.
•
Reverse ETL tools enable you to automate and schedule your data syncs.
•
They also provide you with a visual interface where you can easily map the fields from your source to your destination.
•
you’re in complete control over how frequently your syncs run.
•
write once, use anywhere architecture, enabling you to send the same data to multiple destinations while also managing all of your syncs in one central platform.
•
Many organizations are now realizing that they no longer need to purchase a traditional CDP in parallel to their existing data warehouse where their data already lives.
•
Having a CDP run alongside your data warehouse is essential to ensure that nontechnical teams have access to real-time data, without engineering dependency.
•
CDP offers direct integrations with a vast ecosystem of tools for marketing, analytics, advertising, customer service, and other functions (a capability unavailable through data warehouse solutions without engineering support)
•
But rather than operating as a separate entity and storing data outside of your current data infrastructure like a traditional CDP does, a Composable CDP is an activation layer that lets you curate audiences, orchestrate journeys, and send your existing data to your frontline marketing tools.
•
Composable CDP lets you start with your current data (wherever it is) and activate it immediately rather than implementing and purchasing an entirely new tool.
•
you don’t have to conform your data to the requirements and constraints of another platform, and instead take advantage of your existing data assets.
•
non-technical users had no ability to access data assets, and data teams were forced to supply ad-hoc CSVs or build and maintain custom pipelines to various downstream destinations to make data available.
•
Traditional CDPs have been around for a long time, with Segment pioneering the space in 2011, but most CDPs didn’t actually set out to solve customer-facing use cases.
◦
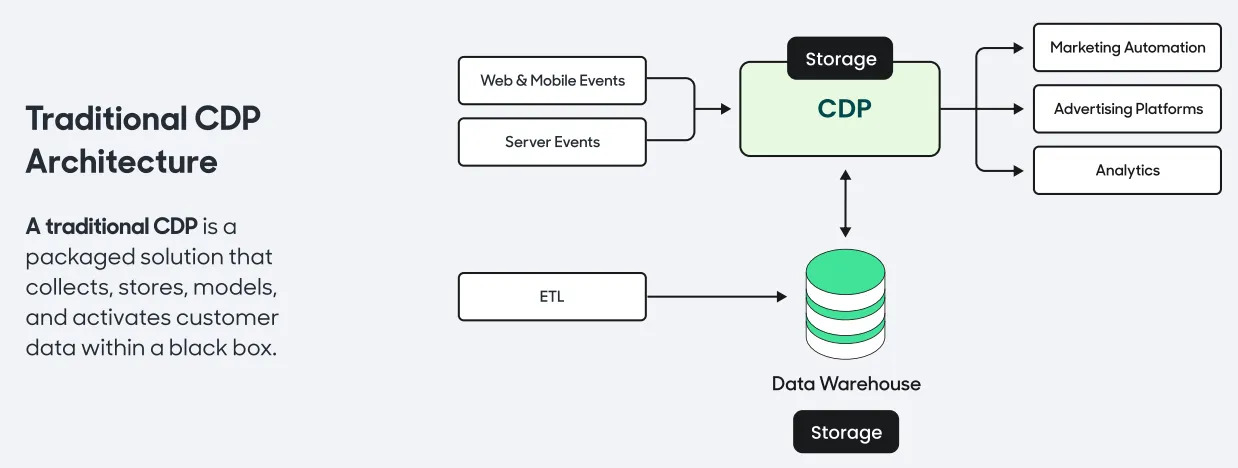
Most CDPs are powered by CDWs under the hood
◦
Traditional CDPs build upon the architecture to create a bundled offering for data collection, audience management, activation. Four components of CDPs are :
◦
Data Storage : store customer data
◦
Identity Resolution : stitch together user actions and attributes across touchpoints
◦
Audience Building : build user cohorts and orchestrate user journeys across marketing channels
◦
Data Syncing : provide out-of-the-box integrations with third-party APIs, enabling one to send audiences directly to operational tools

•
Composable CDP doesn’t act as a black box that stores and manages your data like traditional CDPs; Composable CDP enables you to activate your data using your existing data collection, storage and modelling practices
•
Think of Composable CDP as a middle layer between data assets and marketing tools
◦

•
Composable CDP is a solution that is technology agnostic. As long as you have a table with columns and rows, your data can be activated–it doesn’t matter whether it’s in a data warehouse, a data lake, a production database, or even a spreadsheet
•
Architecturally, all Data Activation platforms are powered by Reverse ETL, which is the process of copying data from your existing data stores and syncing it to your operational systems. The reality is that a Composable CDP is the only solution that lets you bring your existing data and take advantage of the full benefits of a traditional CDP without the negative implications.
•
Fundamental problems with Traditional CDPs
◦
Storage and Data Ownership : creates a second source of truth because it forces you to store and manage data outside existing data infrastructure
◦
Flexiblity : designed to collect clickstream data (e.g., page view, abandon cart, session length), so doesn’t have an understanding of separate first-party data. As built around user and account-based model, means you can’t leverage custom data models or first-party attributes without complex engineering work
◦
Time-to-Value : implementation takes ~6 months. When you want to add a new data source, you have to build new pipelines
◦
Incomplete Data : can’t leverage first-party attributes like income, age, gender, address or the custom data models your data team has built without undergoing big engineering work
◦
Cost : expensive because every feature is bundled together
◦
examples that highlight the limitations
▪
traditional CDPs have no understanding of custom objects that are unique to your business (e.g., local stores, products, propensity models).
▪
With a traditional CDP, you can send an email to cart abandoners, but you can’t send that same email with a local store incentive.
▪
With a traditional CDP, you can show ads to people who visited a specific page, but you can’t ensure those ads aren’t shown when the product is out of stock.
▪
With a traditional CDP, you can send an SMS about a new promotion, but you can’t send that same SMS to people who have a high propensity to redeem it.
•
Advantages of Compoasable CDP
◦
Modularity: You have full control to choose what technologies and processes you use for data collection, storage, modeling, and activation. This allows you to tailor your architecture to the specific organizational outcomes you’re looking to drive.
◦
Flexibility: A Composable CDP gives you immediate access to any and all of your data–not just your clickstream events. Ultimately this means you can leverage any data type to easily accommodate the complex breadth of your use cases.
◦
Compatibility: Since a Composable CDP is technology agnostic and integrates with any data infrastructure, it easily adapts to future infrastructure changes so you can avoid tech-debt and vendor lock in.
•
Exemplary Inputs for Audience build-up
•

•
Security
•
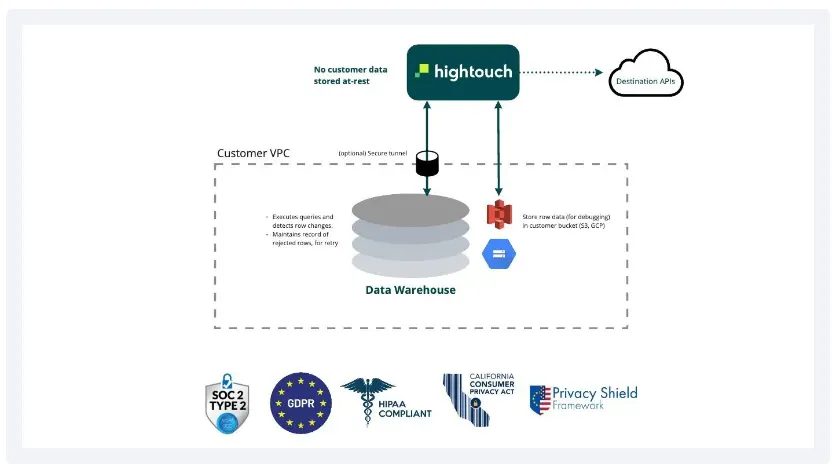
•
2012 : “The First Cambrian Explosion” - adoption of cloud infrastructure with AWS Redshift
•
Redshift was the very first cloud MPP (Massively Parallel Processing) data warehouse run entirely in the cloud
•
Whereas most relational databases at the time were row-oriented, Redshift was built on a columnar structure, making it ideal for storing large amounts of data in various formats from various systems. This made firms of any size easier to do analytics because it got cheaper
•
2016 : market shifted again with the rise of Snowflake, it built the first fully managed SaaS platform for analytics. Removed all of the underlying maintenance that came with Redshift and successfully separated storage and compute resources. The result was a platform that was dramatically faster and cheaper than Redshift
•
With the rapid adoption of Snowflake and speed and capabilities that came with the platform, data engineers quickly realized that they no longer needed to use conventional ETL tools
•
With platforms like Snowflake, data engineers could cost-effectively load raw data into the warehouse and transform it afterward. This gave rise to a new process known as ELT (Extract, Load, Transform)
•
Using ELT, data is transformed using the computing power of the warehouse
•
Modern Data Stack Architecture

•
◦
Data Acquisition
◦
Event Tracking
◦
Data Integration
◦
Storage / Analytics
◦
Data Transformation : takes place in data warehouse, focused on properly formatting and validating data to standardize, replicate, delete, or even restructure as it’s ingested into warehouse. Main focus is data modeling : represents specific data elements and connections
◦
BI : persisting the data within the analytics layer to a visualization tool by connecting directly to the data warehouse
◦
Data Orchestration : With all of the layers in a modern data stack and the various data pipelines that come with it, managing dependencies between various layers, scheduling data jobs, and monitoring everything can be quite difficult. Data orchestration solves this problem by automating processes and building workflows within a modern data stack. With data orchestration, data teams can define tasks and data flows with various dependencies. Data orchestration is based on a concept known as DAG (direct acrylic graphs), or a collection of tasks that reflect the relationships and dependencies between various data flows. Data engineers use data orchestration to specify the order in which tasks are completed, how they’re run, and how they’re retried (e.g. when X data is ingested trigger Y transformation job). With data orchestration, engineering teams can easily author, schedule, monitor, and execute jobs in the cloud.
◦
Data Governance : 1/ data observability, 2/ data cataloging
▪
Observability : monitoring health of data by analyzing data freshness, data ranges, data volume, schema changes, and overall data lineage
▪
Cataloging : understanding exactly what data exists and where it exists
◦
Data Activation : democratizes the data within the warehouse using Reverse ETL to sync it back to downstream tools, and it enables a number of use cases:
▪
Marketing: sync custom audiences to ad platforms for retargeting and lookalike audiences
▪
Sales: enrich data in Salesforce or Hubspot (e.g. lead score, LTV, product usage data, etc.)
▪
Success: use product engagement data to reduce churn or identify upsell opportunities
▪
Finance: update ERPs with the latest inventory numbers and sync customer data into forecasting tools
•
Composable CDP must
◦
run on your own infrastructure
◦
be schema-agnostic
◦
be modular and interoperable
◦
provide unbundled pricing
•
Functionality | Traditional CDP | Composable CDP |
Event Collection | SDK that collects and loads events into the CDP’s infrastructure | SDK that collects and loads events into your data warehouse or streams directly to downstream tools |
Real-Time | Supports event forwarding directly to your destinations | Supports event forwarding to your destinations and streaming from your warehouse tables |
Identity Resolution | Unify profiles using only the event data that lives in CDP | Unify any & all of the customer or entity data in your warehouse (i.e., events, ML predictions, related objects) |
Identity Graph | Owned and managed by CDP vendor | Owned and managed by you in existing infrastructure |
Schema | Limited to users and accounts | Supports any custom entity or object (e.g., households, playlists, etc.) |
Audience Management | Build audience cohorts by grouping users or accounts into segments | Build audience cohorts by grouping users, accounts, or any related model into segments |
Storage | Data is stored and duplicated outside of your infrastructure | Data is stored in existing cloud infrastructure |
Data Activation | CDP to destination | Warehouse to destination |
Reverse ETL | Add-on feature separate from CDP data storage | Core activation capability built into platform architecture |
Analytics | Limited to behavioral data and clickstream events | Flexible to any data in warehouse |
Implementation | 6-12 month average implementation time after contract signature | 100% of customers are live with a production use case at the time of contract signature |
Proof of Concept Testing | Not available | 2-3 weeks for SMB
4-6 weeks for enterprise |
Data Retention | 1-3 years | Unlimited lookback and history |
Cost | Bundled; full platform fee plus MTU (Monthly Tracked User) billing |
•
Growth Initiatives
•
Podcasts : Lenny’s Podcast
•
Youtube : Dropshippers
•
D2C Brand Aggregators
Martech for 2024 Report by Scott Brinker
•
Shopify’s Investments
•
•
The metric used to measure usage corresponds to how the customer is extracting value from the product
•
UBP is becoming increasingly prevalent within SaaS, replacing more traditional subscription- and seat-based pricing models
•
A key differentiator for UBP versus other pricing models is that you aren’t limiting the number of users who have access to your software
•
Software buying has changed
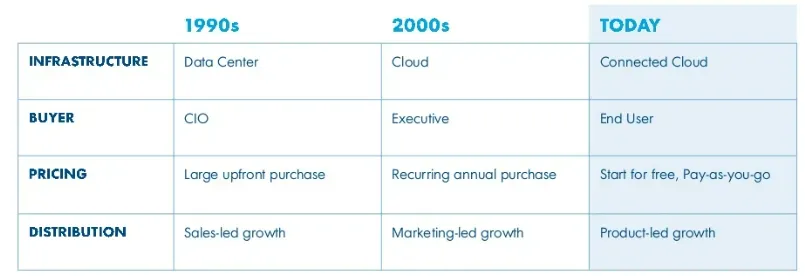
◦
And valuations reflect that
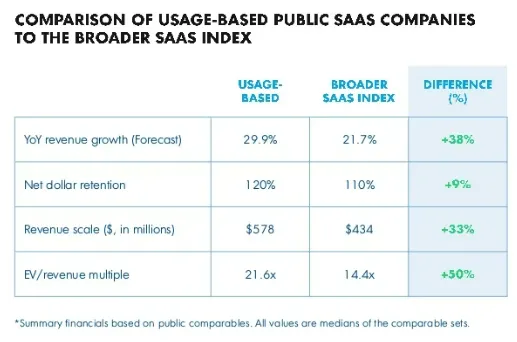
•
How did we get here?
◦
Automation: Software increasingly automates manual processes. The more successful a product is, the fewer user seats a customer needs. Seat pricing doesn’t scale with the value of automation.
◦
AI: AI takes automation a step further, eventually eliminating the need for whole teams of people for ongoing tasks. Monetization can no longer be tied only to human users of a product.
◦
API: For many of the fastest-growing software companies, the value is in the API—software talking directly to other software—rather than the UI. There doesn’t need to be a user to see value.
•
How to add predictability in UBP
◦
“Gift Card” model where the customer can flexibly draw down usage
◦
Roll over unused credits in exchange for a larger commit
◦
Tooling to monitor and alert usage trends for customer
•
If revenue is consumption-based, invest heavily in predicting consumption
◦
How long does it take to deploy the solution before usage begins?
◦
What will the ramp-up of usage look like in the initial period (quarter, year)?
◦
Will this usage be sustainable after initial benefits are realized?
◦
When will network-effects adoption kick in and how fast?
•
Usage-based SaaS companies spend more on R&D than their sales and marketing peers.
•
Post-sale, your CS team takes over to drive customer adoption. They initially focus on driving adoption of key features that create long-term stickiness such as setting up integrations and shared dashboards or working with client teams to identify new use cases.
•
Developing ability to predict usage - this is one of the best investments you can make going into a consumption-based pricing strategy. Not only does it help predict revenue for your business, but it’s valuable information to your customers as well.
•
Platforms
•
WooCommerce
•
Salesforce Commerce Cloud
•
Shopify
•
BigCommerce
Relevant eCommerce players
•
Alloy Automation
•
Rutter : building a universal API for commerce platforms;
◦
Similar to the financial market before Plaid, the e-commerce market is split across hundreds of platforms, such as Shopify, Squarespace, Amazon, and others. Each of these platforms has its own app store or its equivalent, and the enterprising e-commerce developer must spend thousands of hours building integrations in order to access the entire e-commerce market.
◦
Rutter is an integration layer letting any e-commerce tool build one integration to access any storefront or marketplace. We do this by providing an abstract schema representing products, orders, and customers. With its support for 20 platforms and growing, Rutter cuts integration time down from 4 years to 2 weeks, helping e-commerce developers get to market faster and build world-class companies.
Relevant Transactions
•
2020.11 : Twilio purchases Segment for $3B
◦
This move allows Twilio to impact the data-insight-interaction-experience transformation process by removing friction from developers using their platform
◦
it gives developers that ability to use data to build more varied applications using Twilio APIs
◦
Twilio needs more growth path and it looks like its strategy is moving up the stack, at least with the acquisition of Segment. Data movement and data residence compliance is a huge headache for enterprises when they build their next generation applications
•
◦
cloud communications platform, today announced the successful completion of its previously announced acquisition of SendGrid, Inc., the leading email API platform
◦
transaction is valued at approximately $3 billion
Interesting Developments
•
◦
Allow customers to search for products by use cases, instead of by product or brand names. For example, you could ask Walmart to return search results for things needed for a “football watch party,” instead of specifically typing in searches for chips, wings, drinks or a 90-inch TV.
◦
rivaling Google’s SGE (Search Generative Experience), which can recommend products and show various factors to consider, along with reviews, prices, images and more.
◦
demonstrated an AI shopping assistant that would let customers interact with a chatbot as they shopped, to ask questions and receive personalized product suggestions, as well.
◦
Different stakeholders in CDPs
▪
Data implementers : person responsible for implementing marketing and analytics tools
▪
Data enablers : person who owns MarTech stack, also responsible for data quality and identity resolution
▪
Data consumers : person in charge of increasing LTV and customer engagement, also owns digital customer experience
◦
Assessing data landscape
▪
Identify all sources of customer data : abbs, websites, internal db, other tools in stack. Define the scope of CDP implementation by understanding how data is collected and integrated
▪
Determine identity resolution architecture : catalog what identifiers are available from each data source. Then determine which ones can be used to identify registered users vs. anonymous, which should take priority when multiple sources are available
▪
Define universal data layer : create a data plan to define data points to collect and naming conventions for each data point across platforms and properties. Align with data engineers and business users on what data to expect in what format
▪
Identify customer data activation systems : identify downstream data activation systems the team will need to feed customer data to through CDP.
▪
Account for privacy regulations and considerations : e.g., CCPA, GDPR

•
기업이 제품이나 서비스를 고객에게 마케팅하기 위해 고려해야 할 4 요소
•
Product, Price, Place, Promotion
•
전략 및 프로세스
◦
Determine USP → Know Customer → Identify Competition → Access Placement Options → Set Promotion Strategy → Review the Marketing Strategy
•
Path to Profitability
◦
Marketing Environment : Customer, company, competitor쌰
◦
Marketing Mix (4P) : Segmentation, targeting, positioning
◦
Profitability Drivers : Customer Acquisition, customer retention, sales per customer, margin
▪
CPC, 구매전환율, 객단가, 수익률, 재방문율등의 목표 뿐만 아니라 BEP 달성 최소 마지노선 요건 파악 중
▪
모든 회사가 무조건 구매전환을 유도해야하는 것은 아니고, 신규 유입이 많은 경우에는 예를 들어 “회원가입” 유도 하는 것도 중장기적으로 효과적인 CRM 마케팅 방법일 수 있음. 일례로, 전체 첫 구매자 중, 56%가 재방문해서 첫구매를 함
▪
신규 방문자는 회원가입 유도 및 체류시간을 높이는 것을 목표로 광고 세
•
iab (한국의 디지털 마케팅 협회같은 곳): Seller-Defined Audiences (SDA)
◦
사용자 ID를 공개하지 않고 OpenRTB 입찰 요청에서 자사 잠재고객 속성을 전달하는 방법을 설명하는 기술 사양
◦
게시자, SSP, DSP 및 DMP 간에 사용자 식별자를 교환할 필요가 없기 때문에 범용 식별자 솔루션과 다름
◦
이 솔루션은 Chrome이 검색 기록을 기반으로 제공하는 Google Topics API 와 다름
•
Publisher : Publisher-provided Identifier (PPID)
◦
개인정보 보호의 중요성이 높아짐에 따라 Publisher 의 PPID는 중요
◦
PPID를 활용하여 교차 화면 게재빈도 설정
◦
PPID를 활용하여 게시자의 잠재고객 타겟팅 강화
•
Google + PPID : Publisher 가 Google Ad Manager (GAM)를 통해 PPID를 Google DV360의 광고주와 공유하여 사용자 식별자가 필요한 특정 기능을 활성화 허용
◦
DV360이 모든 게시자의 PPID를 집계하여 자사 데이터 활성화 (오디언스 세그먼트)를 확장
◦
Google은 PPID 식별자를 절대 공개하지 않음 - 개인 정보 보호 우선
•
The Trade Desk (TTD) (세계에서 제일큰 미국 DSP 회사) : Unified ID 2.0 (UID2)
◦
익명성 & 개인정보보호 & 사용자 투명성 및 정보 제어
◦
오픈 소스 : UID2에 대한 사용은 오픈소스; 누구나 무료로 사용 가능
◦
Liveramp, Oracle, Nielsen, comscore, OpenX, PubMatic, Magnite, SPOTX등 애드테크 업계의 Big기업들이 해당 생태계에 참여
•
LiveRamp : RampID
◦
•
EU - NetID
◦
•
OTT 플랫폼 : Identifier for Advertising (IFA)
◦
•
NBC Universal : NBCU ID
◦
How to measure Marketing Resources Spent
•
There are two ways. MMM and MTA. Both are underpinned by User object and Event object
•
MMM (Mixed Media Modeling) :
•
MTA (Multi-Touch Attribution) : Figuring out the balance between first touch and last touch in terms of weights you allocate to each event to measure ROAS
Golden Stack
•
Amplitude for CDP, Product Analytics
•
Customer io for B2C → Braze for B2Bin the future for email
•
Snowflake for Database
•
Hightouch for ReverseETL to streamline data tools
